Web designers spend hours painstakingly marking up code. They need a way to save those changes. The *.html file extension does that.
Moreover, front-end designers can have some neat tricks up their sleeves to make interesting features on a webpage. Content boxes, borders, shadows, or a background surrounding an image are just a few examples.
It can make you wonder how they did it, but more importantly, can you do it too?
Chances are that you can by downloading the HTML code, making some edits, then saving your file with the changes.
Is that allowed? It sure is! What you should not do is clone a website for nefarious purposes.
Testing or archival purposes should be the reason for downloading any website source code.
1. Use Your Browser’s “Save as” Options to Download HTML Code from a Website
Step 1: Open the website you want to download the HTML code from
All major browsers have the ability to open, edit, and download the source code for any website you visit.
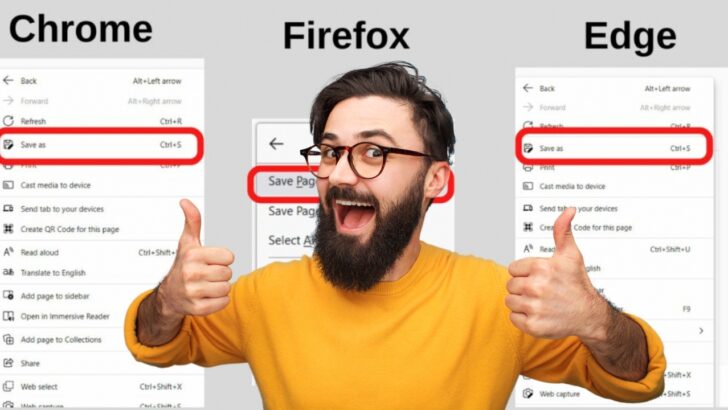
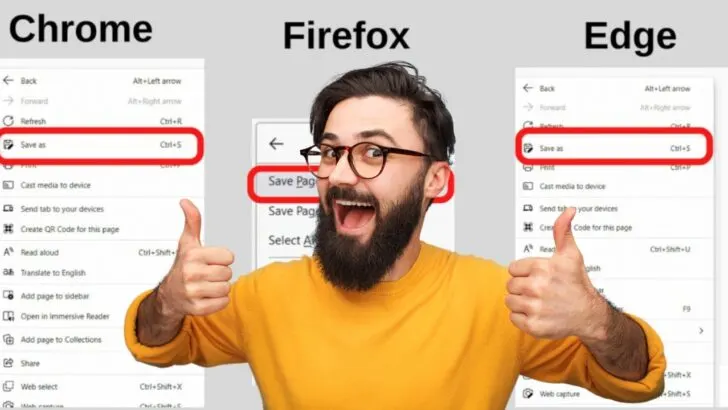
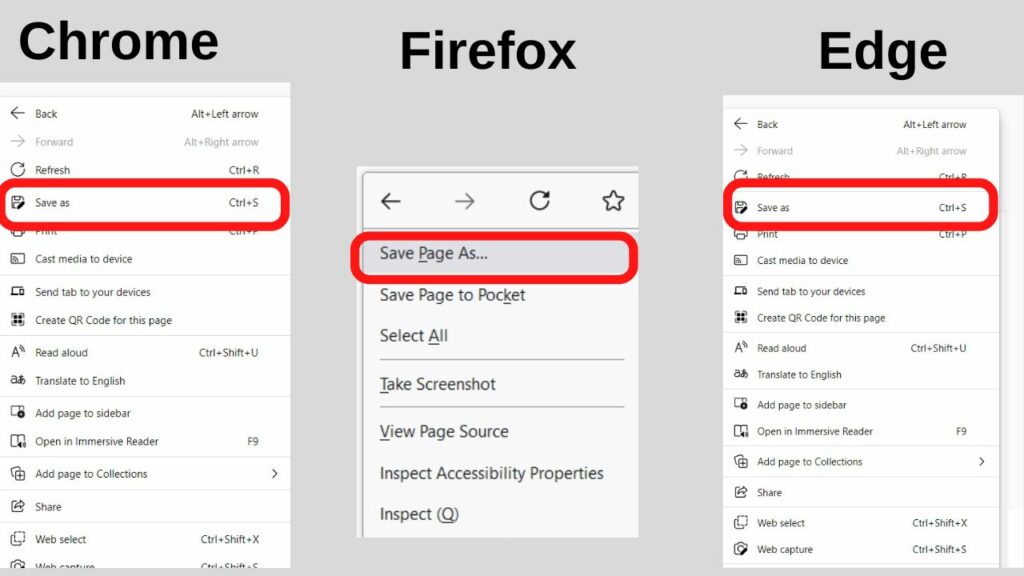
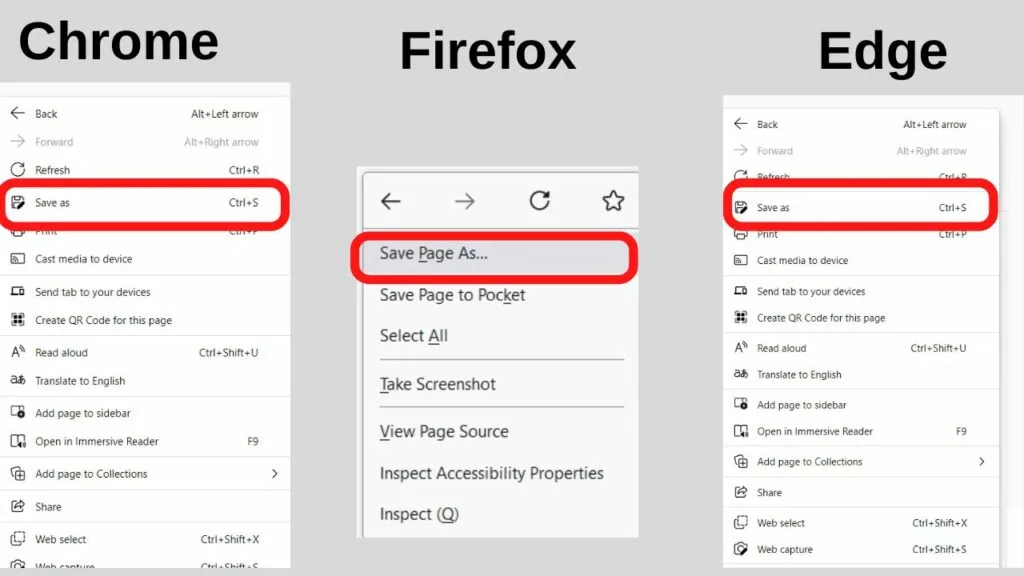
Step 2: Open the Context Menu and select “Save as…”
The context menu is opened when you right-click on a webpage. Select the “Save As…” option.
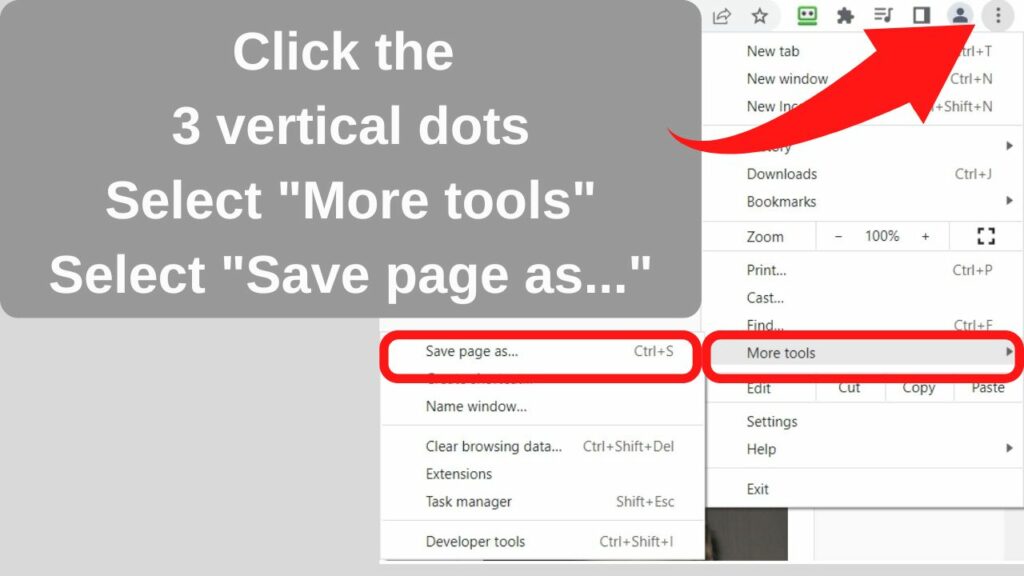
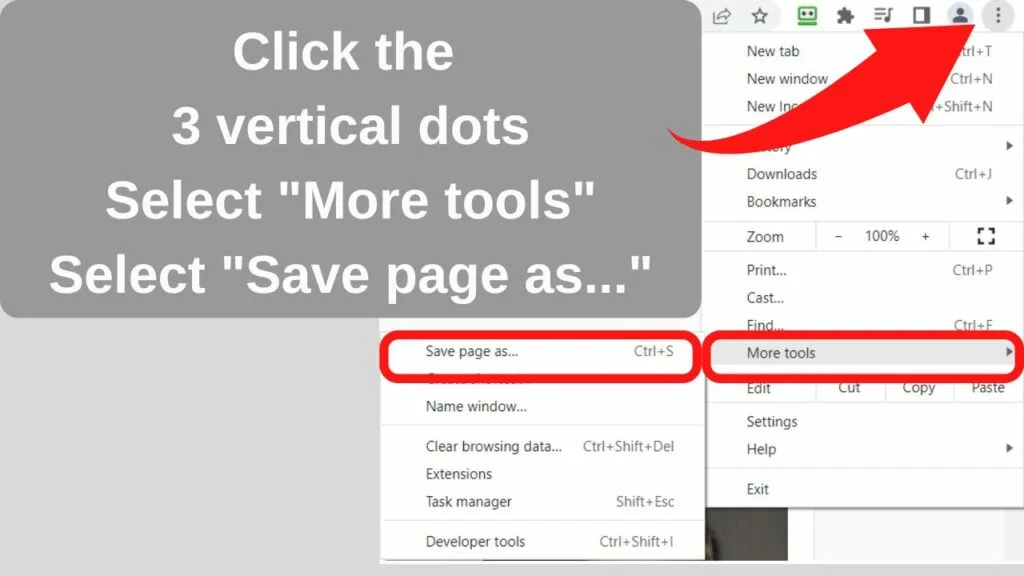
If you are using a tablet without a mouse, the same menu can be accessed by tapping on the three dots to the top right of your browser pane, selecting “More tools”, then “Save Page As…”
The shortcut keys on Windows machines to open the save menu is CTRL + S.
On a Mac, use Command + S.
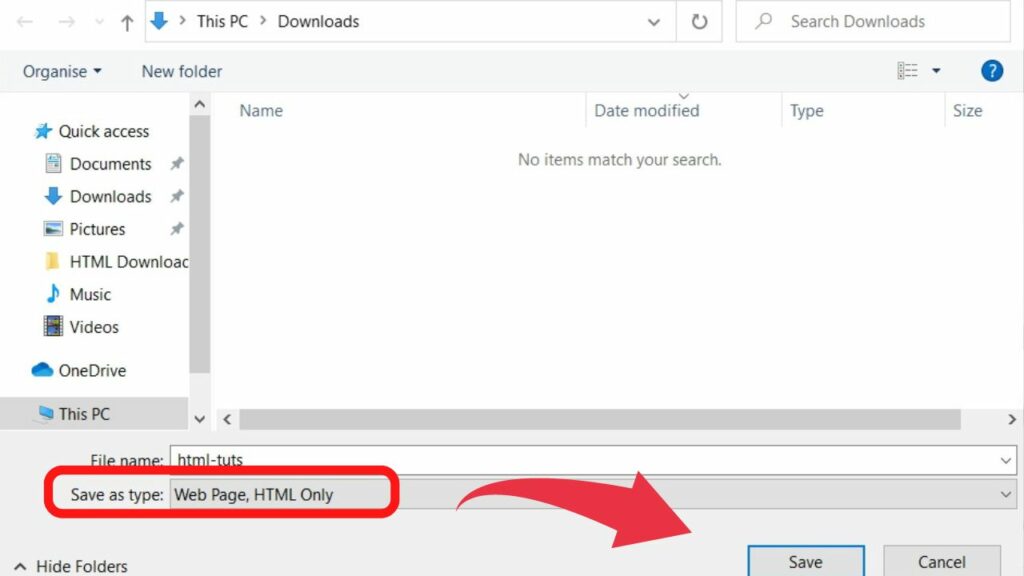
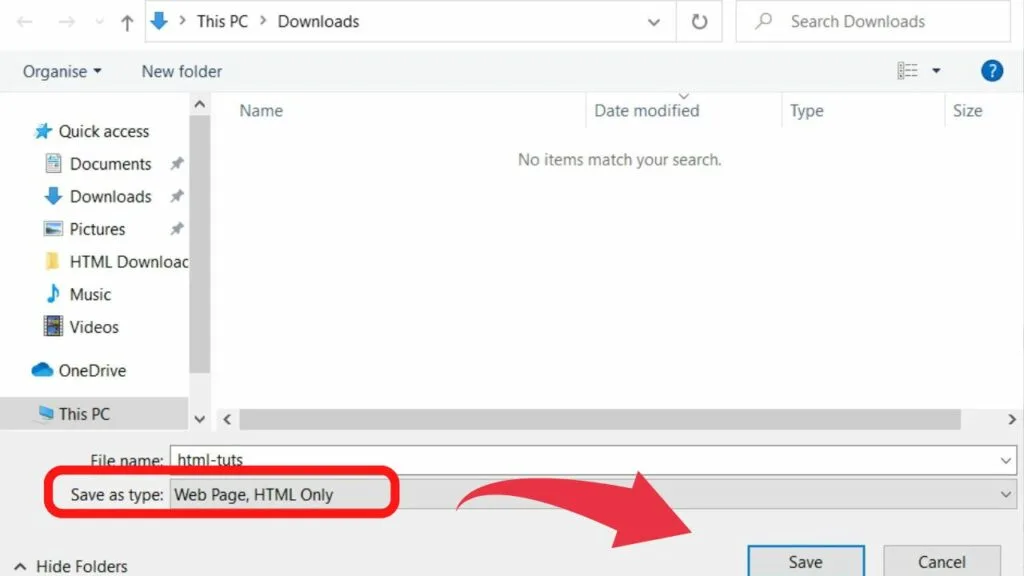
Step 3: Save the file type as “Webpage, HTML Only”
The save as dialogue box is where you can set the file name and assign a folder/directory to save your file. Usually, it will be pre-set to either your downloads folder or the last directory you saved a file in.
Step 4: Open the HTML file in your browser or show in folder
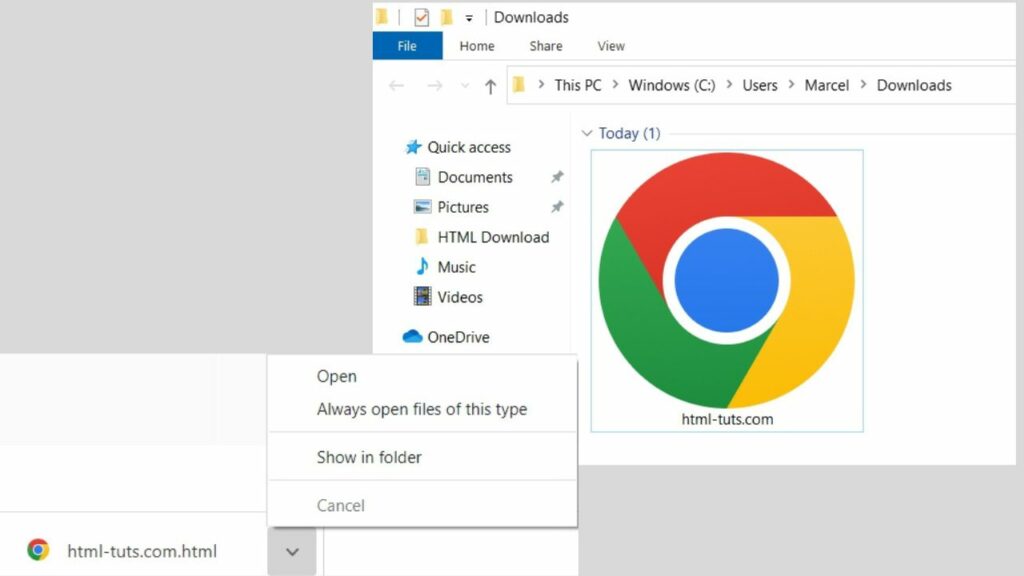
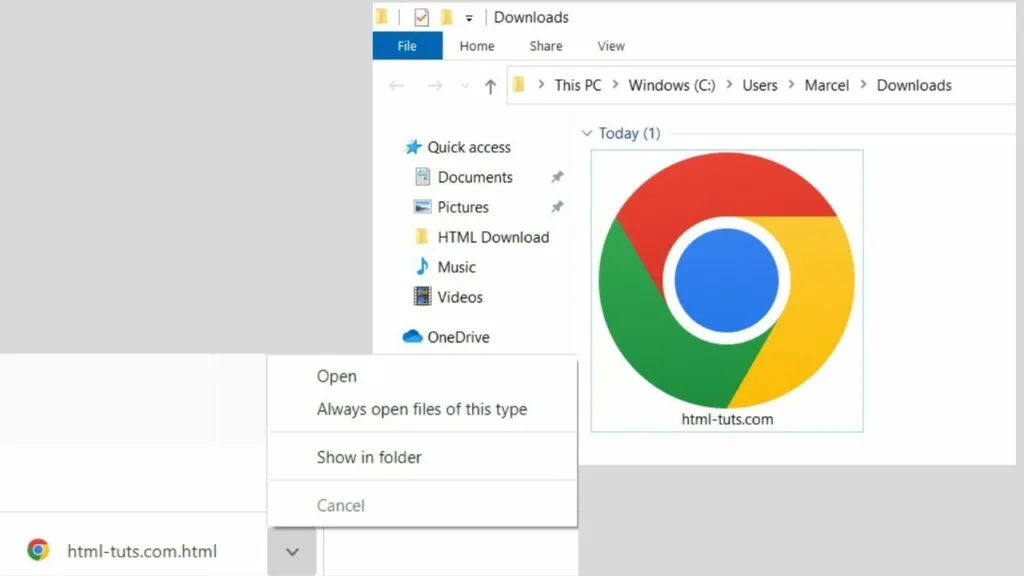
As soon as your file starts downloading, a notification shows in the browser. Once complete, click on the arrow to show the options.
Selecting “open” will open the HTML file in your browser.
Select “show in folder” to see where your file is stored on your local drive, then move it if need be.
2. Use the Browser Inspector Tool to Download HTML Code from a Website
Step 1: Access the inspector tool in your browser
The inspector tool is part of the web developer tools in browsers.
To access it, click or tap on the three dots (or lines) at the top right of your browser pane.
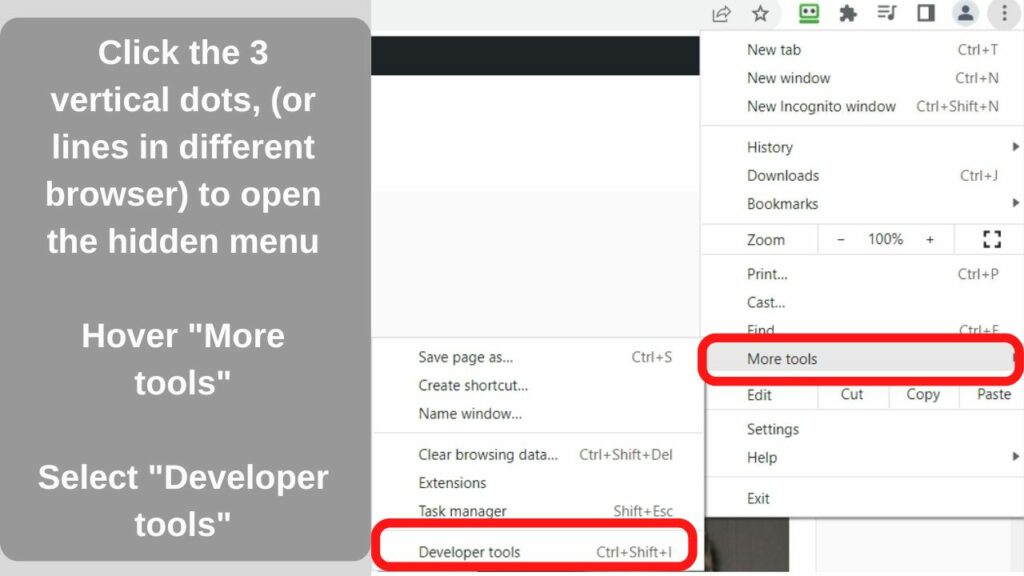
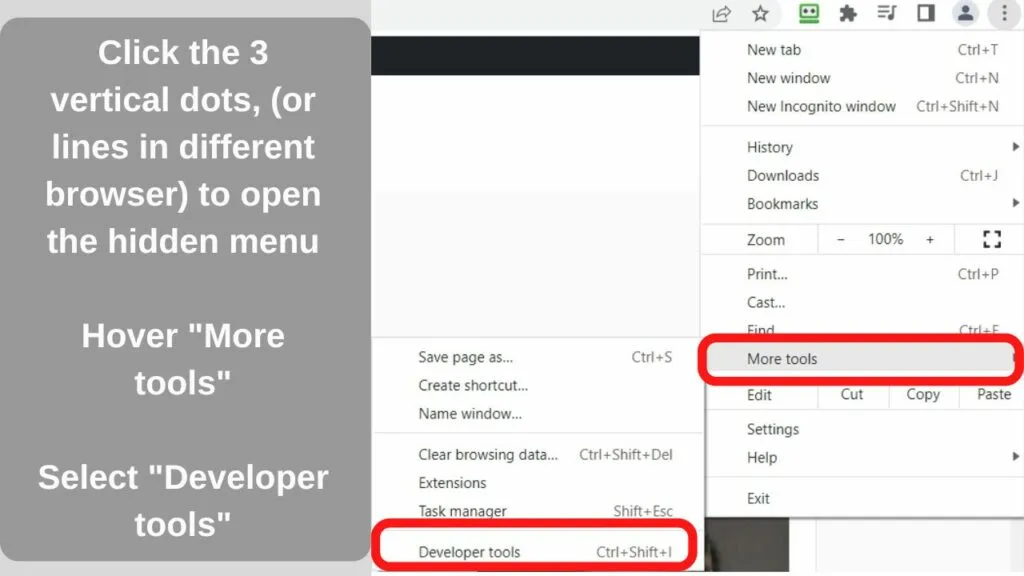
Microsoft Edge and Chrome – Select “More tools”, then select “Developer Tools” The Keyboard shortcut on Windows is CTRL +SHIFT + I. On Mac, use the COMMAND key instead of CTRL.
Firefox – Select “More tools”, then “Web Developer Tools”. The Firefox shortcut is CTRL + SHIFT + C. On a Mac, COMMAND + SHIFT + C.
Step 2: Select the “Sources” tab
When you first use the Inspector view, the console tab opens. The top navigation menu lets you view different source codes. Select the “sources” tab to see all sources on the page.
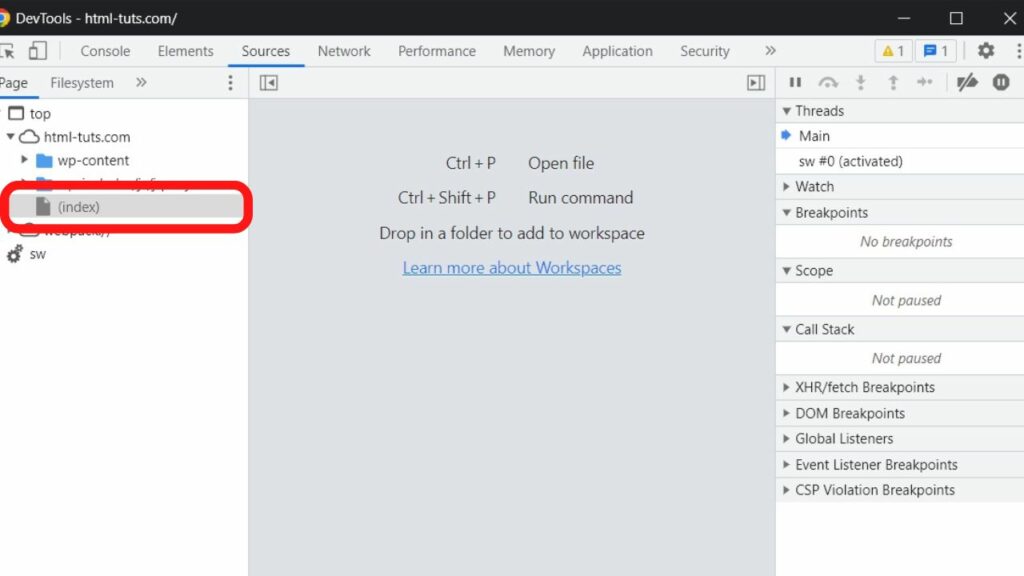
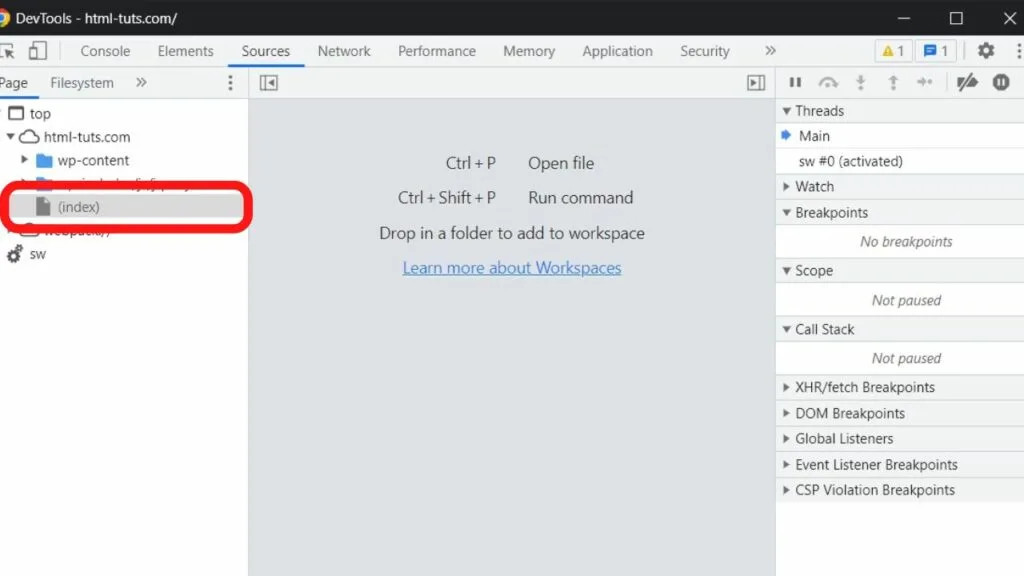
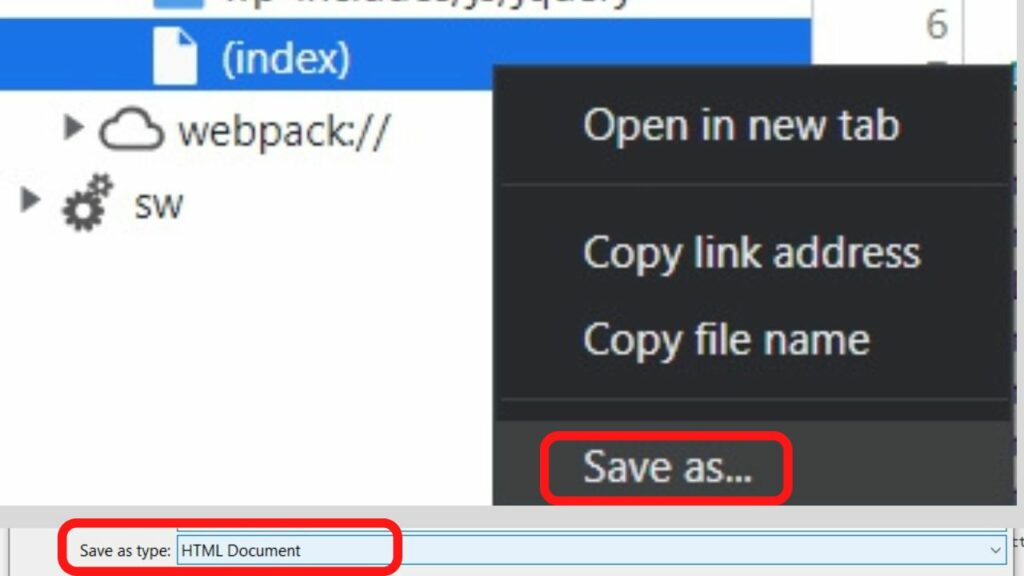
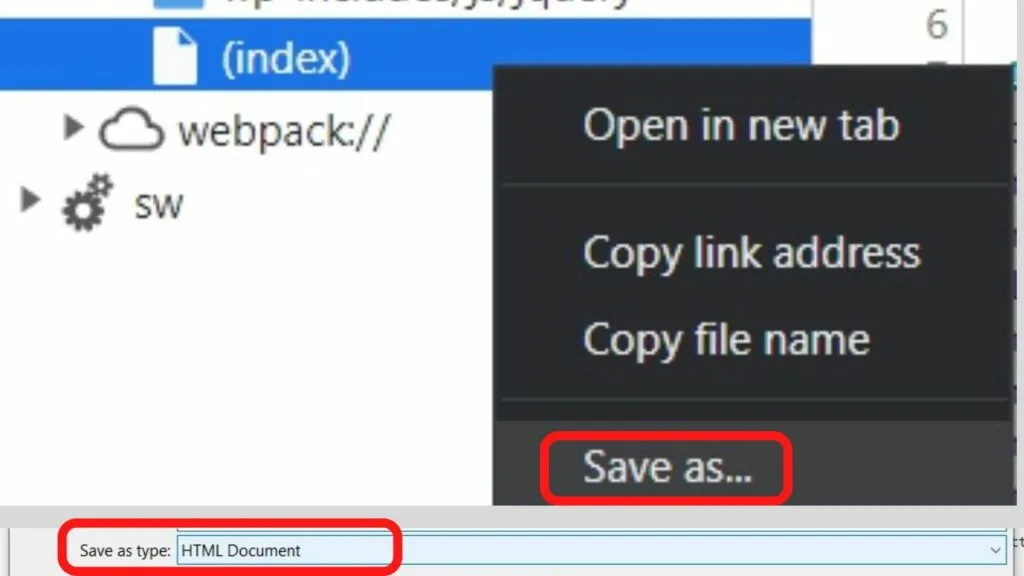
Step 3: Right-click on the “index” file
The left column will show you the source files in use. Right-click on the index file.
Step 4: Save the file as a HTML Document
In Chrome Devtools, the “Save as type” shows it is an HTML document. If the browser does not detect an HTML document, use the *.html file extension. (replace * with the file name you are saving).
Step 5: (optional) Download CSS and JavaScript folders
Using Devtools, or Web Developer Tools, the sources tab reveals all of the folders that are in use. The index file is only the index.html file. There are likely to be others.
You can navigate through the various sources and repeat the save options for any file you want. The only thing you need to change are the file extensions. Use *.js to save JavaScript files and *.css to save CSS style sheets.
The Different Save Options in All Browsers Explained
Webpage, HTML Only (*.htm, *.html)
HTM and HTML files are the same. The only difference really is the one letter (L). The HTM file was common in early versions of Microsoft webpage design tools. Both file types contain HyperText Markup Language.
Webpage, Single File (*.mhtml, *.mht, *.eml)
The single file format is a web archive file that uses MIME (Multipurpose Internet Mail Extension). This saves all HTML, and linked directories such as CSS and images in a single page file. The *.mhtml file extension is the more common file name for single files. The *.eml is generally used to save email messages including the header, subject, and any attachments.
Webpage, Complete (*.htm, *.html)
Despite the file names having the same extension, when you save a “Webpage, Complete” file rather than the HTML-only option, an additional folder is downloaded. This contains the linked assets within the source file including JavaScript, images, CSS, audio, and video files.
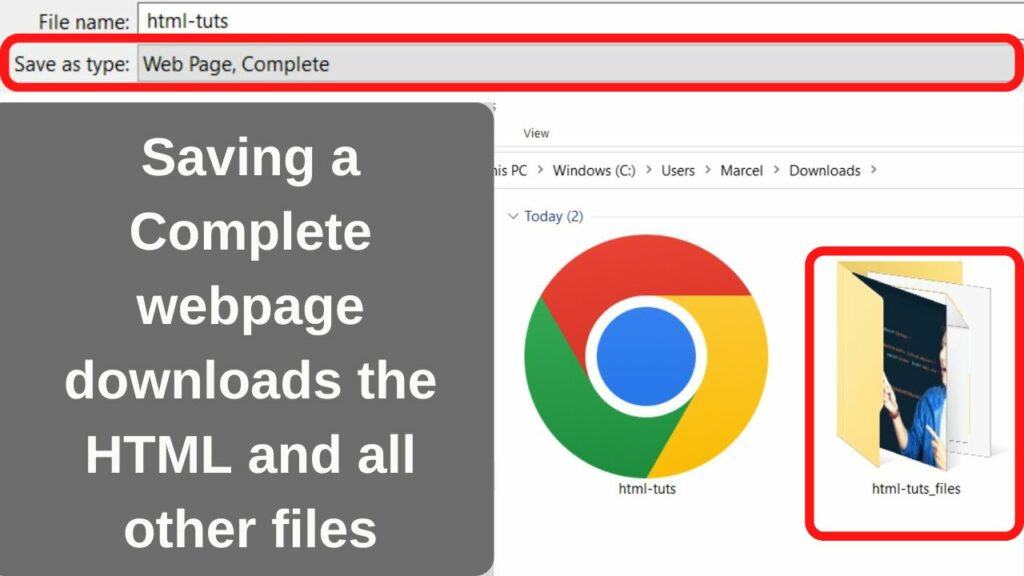
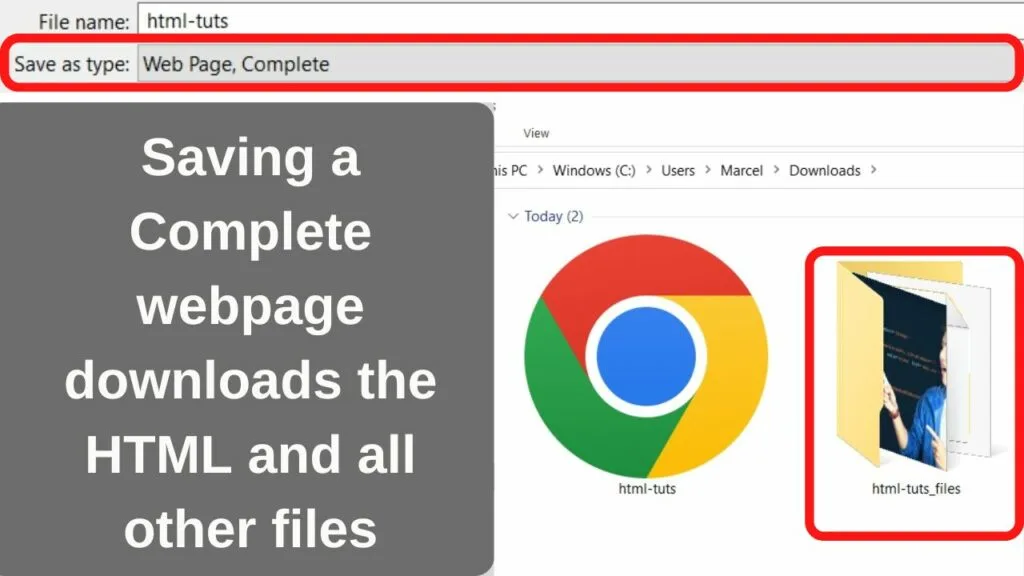
If you want to save a webpage as it looks on your screen, you will need the style sheet too.
Otherwise, the HTML-only version can look as though it is broken because there will be no styling rules such as page margins, borders, line spacing, or any custom fonts being called up from the style sheet.
How to view and edit the HTML of any website
Any HTML files can be opened in your browser.
To edit the HTML of a website, you can use a plain text editor such as Notepad, or alternatively, use a source code editor, such as KompoZer, or Visual Studio Code.
Both are free source code editors with auto code completion.
Using a source code editor is simpler because it helps eliminate errors such as missing an opening or closing bracket.
And it works like Google’s autosuggest function but for source code only. As an example, when you type “border”, it presents you with a range of properties you can assign with a click.
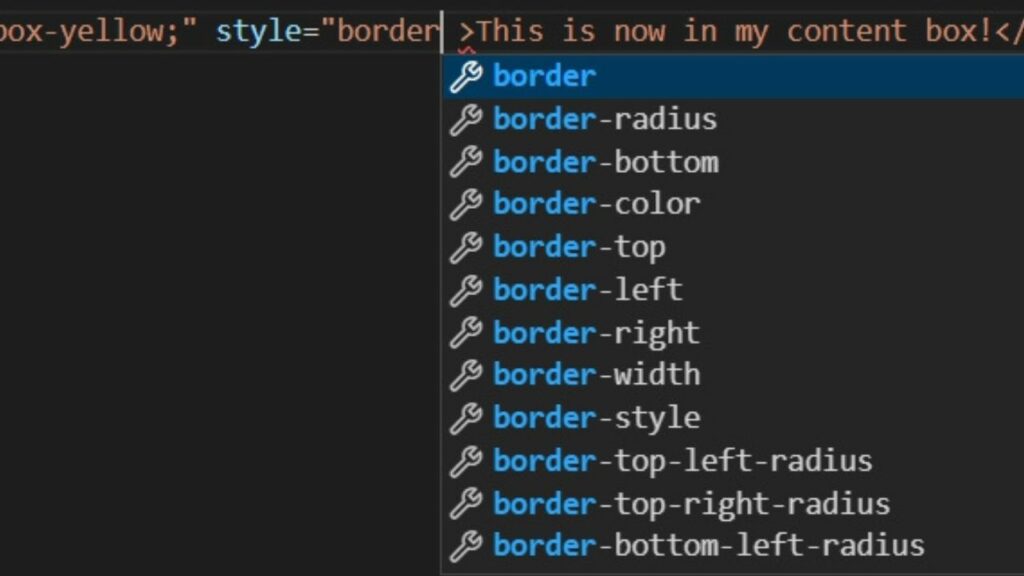
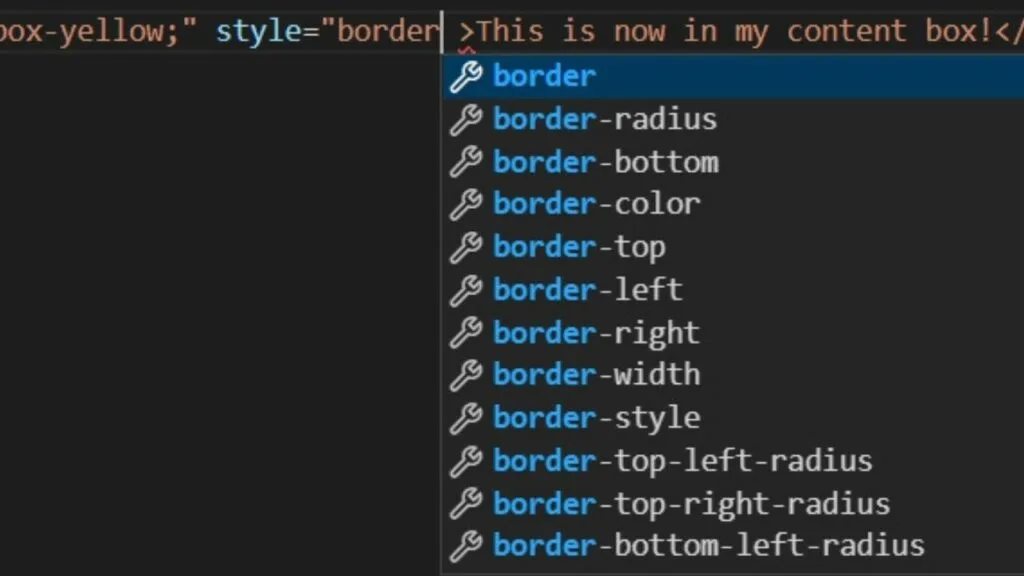
It is much faster to edit HTML files using a source code editor than it is manually with a plain text editor.
Once edits are done, open it in your browser to see the changes in effect.
Why Saving a Webpage, Complete package does not always work
When you save a website, all you can save is the front-end files.
That is the HTML, the CSS, and the JavaScript.
Where problems creep in when saving a copy of a website locally is when server-side scripting is used to load data contained on the server.
These are back-end programming language scripts that browsers cannot fetch.
Many modern websites use different back-end scripting languages, such as React and Node.js using @import or similar commands.
These files cannot be downloaded because the browser does not access them. The server sends them when a script is executed by the browser.
API scripts can also be called to load content hosted on an external library. To reach an external source to load the content, an Internet connection would be required.
Offline viewing and editing would not work.
Most smaller websites are straightforward to save the HTML for local use.
Dynamic websites may or may not be downloadable. Particularly, corporate websites that implement security measures to prevent their website from being cloned.
Now, before we wrap this article up, here’s a short summary (see next paragraph)
How to Download HTML Code from a Website
Right-click, select “Save as” and then choose “Webpage, HTML Only”. The shortcut keys CTRL + S on Windows, or Command + S on Mac open the same save options. Another way is to use a browser inspector tool. Select the sources tab, right-click on the index file and save it with the *.html extension.